Fictions et (con)figurations
Quelques réflexions sur la constitution de bases de données pour les études littéraires
Déroulement de la conférence
- Études littéraires et bases de données : Quelques repères
- La base de données « Figurations » : Bilan prospectif (et un peu critique)
Première partie : Études littéraires et bases de données
Trois types d'entités
- Textes
- Attributs
- Relations
Les bases de données textuelles
1949 - Roberto Busa débute la mise en place du Corpus Thomisticum


1972 - Création du Thesaurus Linguae Graecae

1976 - Création de la Oxford Text Archive (OTA)
- Premier dépôt d'éditions électroniques de textes pour la recherche
- Fondateur : Lou Burnard
En France, création de Frantext
- Encodage de 1000 textes français
- Pour servir d'exemples pour Le Trésor de la langue française
1987, 1990 - Hypercard et Hypercard 2.0

1991 - Beowulf Workstation

Années 1990 et 2000 - Multiplication des projets d'édition numérique et mise en ligne des grands corpus textuels
- 1996 - William Blake Archive
- 1997 - The Orlando Project
- 1998 - Frantext
- 2001 - Thesaurus Linguae Graecae
Technologies de stockage
- Fichiers textes
- Bases de données relationnelles
- Bases de données NoSQL orientées document : MongoDB, Couchbase
- Fichiers et/ou bases de données nativement XML : Exist, Oracle Berkeley DB XML
Technologies de stockage (2) - La TEI
- Novembre 1987 - Création de la TEI
- Mai 1994 - Première version (P1) des Guidelines for Electronic Text Encoding and Interchange
Technologies de stockage (3) - XML - Oxygen

Technologies de stockage (4) - XML-TEI
<text>
<front>
<div>
<head>Préface de l’auteur</head>
<p>Les <hi rend="i">Rougon-Macquart</hi> doivent se composer d’une vingtaine de romans.
Depuis 1869, le plan général est arrêté, et je le suis avec une rigueur extrême.
L’Assommoir est venu à son heure, je l’ai écrit, comme j’écrirai les autres,
sans me déranger une seconde de ma ligne droite. C’est ce qui fait ma force.
J’ai un but auquel je vais.</p>
<p>Lorsque L’<hi rend="i">Assommoir</hi> a paru dans un journal, il a été attaqué
avec une brutalité sans exemple, dénoncé, chargé de tous les crimes.
Est-il bien nécessaire d’expliquer ici, en quelques lignes, mes intentions d’écrivain ?
J’ai voulu peindre la déchéance fatale d’une famille ouvrière, dans le milieu empesté de nos faubourgs.
Au bout de l’ivrognerie et de la fainéantise, il y a le relâchement des liens de la famille,
les ordures de la promiscuité, l’oubli progressif des sentiments honnêtes, puis comme dénouement la honte et la mort.
C’est la morale en action, simplement.</p>
<p>L’<hi rend="i">Assommoir</hi> est à coup sûr le plus chaste de mes livres.
Souvent j’ai dû toucher à des plaies autrement épouvantables. La forme seule a effaré.
On s’est fâché contre les mots. Mon crime est d’avoir eu la langue du peuple.
Ah ! la forme, là est le grand crime ! Des dictionnaires de cette langue existent pourtant,
des lettrés l’étudient et jouissent de sa verdeur, de l’imprévu et de la force de ses images.
Elle est un régal pour les grammairiens fureteurs. N’importe, personne n’a entrevu que ma volonté
était de faire un travail purement philologique, que je crois d’un vif intérêt historique et social.</p>
<p>Je ne me défends pas d’ailleurs. Mon œuvre me défendra. C’est une œuvre de vérité, le premier roman sur le peuple,
qui ne mente pas et qui ait l’odeur du peuple. Et il ne faut point conclure que le peuple tout entier est mauvais,
car mes personnages ne sont pas mauvais, ils ne sont qu’ignorants et gâtés par le milieu de rude besogne
et de misère où ils vivent. Seulement, il faudrait lire mes romans, les comprendre, voir nettement leur ensemble,
avant de porter les jugements tout faits, grotesques et odieux, qui circulent sur ma personne et sur mes œuvres.
Ah ! si l’on savait combien mes amis s’égayent de la légende stupéfiante dont on amuse la foule !
Si l’on savait combien le buveur de sang, le romancier féroce, est un digne bourgeois, un homme d’étude et d’art,
vivant sagement dans son coin, et dont l’unique ambition est de laisser une œuvre aussi large
et aussi vivante qu’il pourra ! Je ne démens aucun conte, je travaille,
je m’en remets au temps et à la bonne foi publique pour me découvrir enfin sous l’amas des sottises entassées.</p>
<p rend="right noindent">ÉMILE ZOLA</p>
<p>Paris, 1<hi rend="sup">er</hi> janvier 1877.</p>
</div>
</front>
</text>
Technologies de stockage (5) - XML-TEI
<div type="edition">
<head>Text</head>
<ab subtype="text" n="2">Text II
<lb xml:id="line_1" n="1"/><name type="animal" key="goat">
<w lemma="αἴξ">αἲξ</w></name> <name type="sacrifice">
<w lemma="θύω">θύεται</w></name>.
<lb/><space quantity="1" unit="line"/>
<lb/><space quantity="1" unit="line"/>
<lb/><space quantity="1" unit="line"/>
</ab>
<ab subtype="text" n="1">Text I
<lb xml:id="line_2" n="2"/><w lemma="ὅδε">τάδε</w> <w lemma="μή">μὴ</w>
<w lemma="εἰσφέρω">ἐσφέρεν</w> <w lemma="εἰς">ἐς</w> τὸ
<lb xml:id="line_3" n="3"/><name type="structure"><w lemma="τέμενος">τέμενος</w>
</name> τοῦ <name type="deity" key="Apollo"><w lemma="Ἀπόλλων">Ἀπόλλω
<lb xml:id="line_4" n="4" break="no"/><supplied reason="lost">νος</supplied>
</w></name> τοῦ <name type="epithet" key="Oulios">
<w lemma="οὔλιος">Οὐλίου</w></name>· <name type="clothing">
<w lemma="ἱμάτιον">εἱμάτιον</w></name>
<lb/><gap reason="lost" unit="line" extent="unknown"/>
</ab>
</div>
Technologies de stockage - XML-TEI (6)
[T]he size of the TEI community is limited by the complexity of the data model and the tools required to implement it, with the result that simpler, procedurally oriented text editing systems such as wikis and Wordpress have garnered more mainstream scholarly users. When what the average scholar wants above all is usability in scholarly tools and interoperability in scholarly resources, there is a tension between more usable technologies and those based on better data models and best practices.
Susan Brown, « Tensions and tenets of socialized scholarship », dans Digital Scholarship in the Humanities, 31(2), p. 292.
Exploitation des données textuelles (1) - Text mining et analyse textuelle automatisée
- Text clustering
- Apprentissage supervisé (Supervised machine learning)
- Topic modeling
Exploitation des données textuelles (2)
Exploitation des données textuelles (2)
Analyse de ponctuation - Adam J. Calhoun (1)

Exploitation des données textuelles (3)
Analyse de ponctuation - Adam J. Calhoun (2)


Les bases de données attributives
Le Roy Ladurie et l'École des Annales

Bases de données attributives et études littéraires
- Catalogues et bases de dépouillements
- Prélia : plusieurs milliers d'articles publiés dans des revues d'art, 1870-1940
- Répertoire des oeuvres hypermédiatiques - NT2
- Bases de données prosopographiques
- Base de données du CIEL
- Base de données sur la Vie littéraire au Québec
La base de données sur la Vie littéraire au Québec
Technologie de stockage
- Bases de données relationnelles : Microsoft Access, FileMaker, MySQL (et MariaDB), PostgreSQL, etc.
Exploitation des donnés attributives
- Analyse statistique et analyse factorielle des correspondances
- Cartographie et géolocalisation
Statistique et ACM

Le geospatial turn in the humanities
The expansion to the web, coupled with the availability of satellite imagery, data providers, and map APIS from Google to OpenLayers, took away the time-consuming aspect of having to acquire basemaps and learn abstruse software. It empowered an entire generation of mappers who were now able to create web maps with just a little bit of programming knowledge.
Todd Presner et David Sheppard, « Mapping the Geospatial Turn », dans Susan Schreibman et al. (dir.), A New Companion to Digital Humanities, Wiley-Blackwell, 2e édition, 2016, p. 204.
Mapping the Republic of letters
Bases de données relationnelles
Technologies de stockage
- Tableurs
- Bases de données relationnelles : Microsoft Access, FileMaker, MySQL (ou MariaDB), PostgreSQL, etc.
- Bases de données NoSQL orientées graphes et triplestores : Neo4J, OrientDB, Virtuoso, RDF4J, etc.
Exploitation des données relationnelles (1) : l'analyse structurale des réseaux sociaux
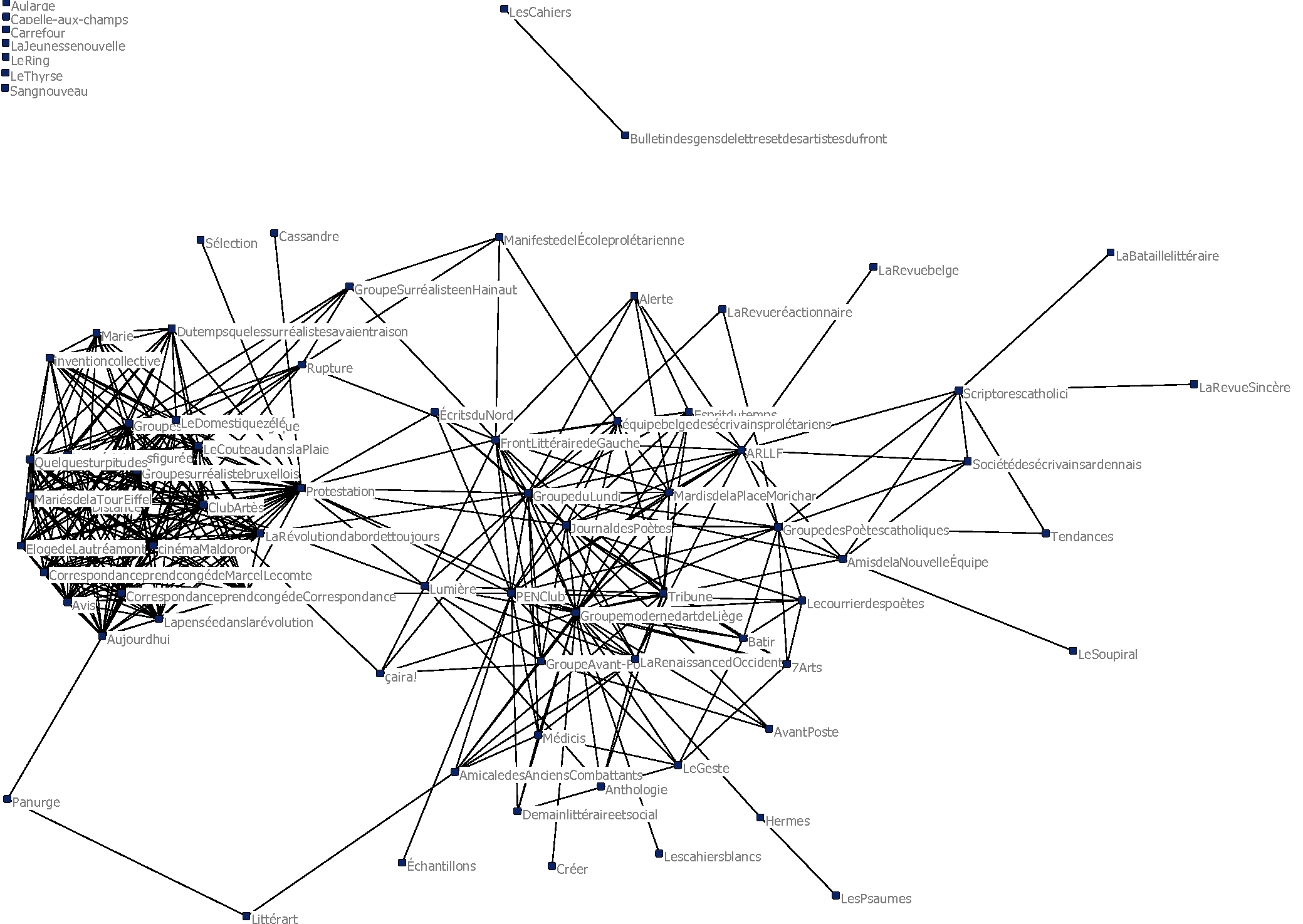
Exploitation des données relationnelles (2) : réseaux de personnages

Analyse des réseaux et études littéraires : quelques critiques
Phenomena in the world of humanistic experience and also in the varied and complex discourse fields of aesthetic documents do not lend themselves to representation within bounded, carefully delimited parameters. The metrics used to weight or characterize humanities phenomena are more complex than single value systems can represent, so a network diagram that shows ““relations” among various nodes in a cultural system, among documents, authors, concepts, and so on, that is grounded in a single metric value for the edge‐node relations, is painfully reductive. Relationships, whether among human beings or humanistic concepts, are dynamic, fluid, flexible, and changeable.
Johanna Drucker, « Graphical Approaches to the Digital Humanities », dans Susan Schreibman et al. (dir.), A New Companion to Digital Humanities, Wiley-Blackwell, 2e édition, 2016, p. 247.
Deuxième partie - La base « Figurations »
Modélisation et conception de la base
Corpus de travail
- Première version de la bibliographie : 529 romans français parus entre 1801 et 2011
- Deuxième version inclut aussi 336 romans québécois parus entre 1950 et 2010
La structure de la base

L'interface de gestion des données
Une base de données hybride
- Entrecroisement de données textuelles et données attributives
- Intégration de préoccupations généralement reservées à l'analyse externe du fait littéraire
- À mi-chemin entre close et distant reading
Une base de données hybride (2)
Like it or not, today’s literary-historical scholar can no longer risk being just a close reader: the sheer quantity of available data makes the traditional practice of close reading untenable as an exhaustive or definitive method of evidence gathering. Something important will inevitably be missed. The same argument, however, may be leveled against the macroscale; from thirty thousand feet, something important will inevitably be missed. The two scales of analysis, therefore, should and need to coexist.
Matthew Jockers, Macroanalysis : digital methods and literary history, Urbana, Chicago and Springfield, University of Illinois Press, 2013, p. 9.
Quelques chiffres (1)
- 129 fiches « Romans » dont 101 ont été révisées et rendues publiques
- 2032 fiches « Personnages »
- 1619 consacrées à des acteurs culturels
- 661 consacrées à des personnages écrivains
- 161 consacrées à des personnages principaux écrivains
Quelques chiffres (2) - Extraits
- Personnages - Descriptions : 11201
- Intertextualité : 3859
- Personnages - Prise de position : 3432
- Personnages - Activités culturelles : 2149
- Personnages - Capitaux : 2634
- Personnages - Éléments de l’environnement : 2061
- Personnages - Langage : 1992
- Médiatisations : 425
- Oeuvres publiées : 408 (en fait, ce champ peut contenir plusieurs extraits)
- Débauche : 377
- Scènes d’écriture : 314
Quelques chiffres (3) - Extraits (suite)
- Autres sphères : 292 (ce champ peut contenir plusieurs extraits)
- Oeuvres projetées : 262 (en fait, ce champ peut contenir plusieurs extraits)
- Identités collectives : 214
- Lieux : 122
Exploitation des données (1) - Recherche plein-texte
Exploitation des données (2) - Statistiques et graphes
Exploitation des données (3) - Recherche avancée
Exploitation des données (4) - L'API
Des oeuvres qui fonctionnent trop bien?
« Jacques Arnaut met à mal [notre] méthode. Par le caractère proliférant de sa dimension métalittéraire, ce roman constitue une œuvre-limite, à ce point imprégnée des considérations et préoccupations qui animent notre projet, qu’elle paraît “insaisissable”. Tout se passe ainsi, à la première lecture, comme si la fiche allait en reproduire intégralement les quelque 600 pages. Quel est l’intérêt de la sélection d’extraits, si tout retient l’intérêt? Les mailles du filet seraient-elles, dans ce cas, trop serrées?
Michel Lacroix, « "Épuiser tous les possibles" : Léon Bopp et la Somme Romanesque », dans Le Gremlin (dir.), « Fictions du champ littéraire », Discours social, vol. XXXIV, 2010, p. 115-116.